Kubernetes: The Unsung Hero of Modern Software
By Puskar Dev • Published: 2/26/2025
Kubernetes In-Depth: Understanding the Engine of Modern Application Orchestration
While a simple view of Kubernetes as an “orchestra conductor” is a good start, its true power and importance in modern software development (as of May 2025) come from its sophisticated architecture and rich set of features. Let’s explore Kubernetes more deeply.
At its heart, Kubernetes is an open-source platform designed to automate the deployment, scaling, and operational management of containerized applications. It’s not just about running containers; it’s about running them resiliently, efficiently, and at scale, abstracting away much of the underlying infrastructure complexity.
The Core Problem: Managing Containers at Scale
Before diving into Kubernetes, remember containers (like those created by Docker). They package an application with all its dependencies (code, runtime, libraries, environment variables, configuration files). This ensures consistency across different environments.
However, for any non-trivial application, you’ll have many containers. This leads to challenges:
- How do you deploy and update these containers across many machines?
- How do you ensure they keep running if a machine or container fails?
- How do you scale them up or down based on demand?
- How do different containerized services find and talk to each other?
- How do you manage their configuration and sensitive data securely?
Kubernetes is designed to solve these problems.
The Kubernetes Detailed Architecture - Under the Hood
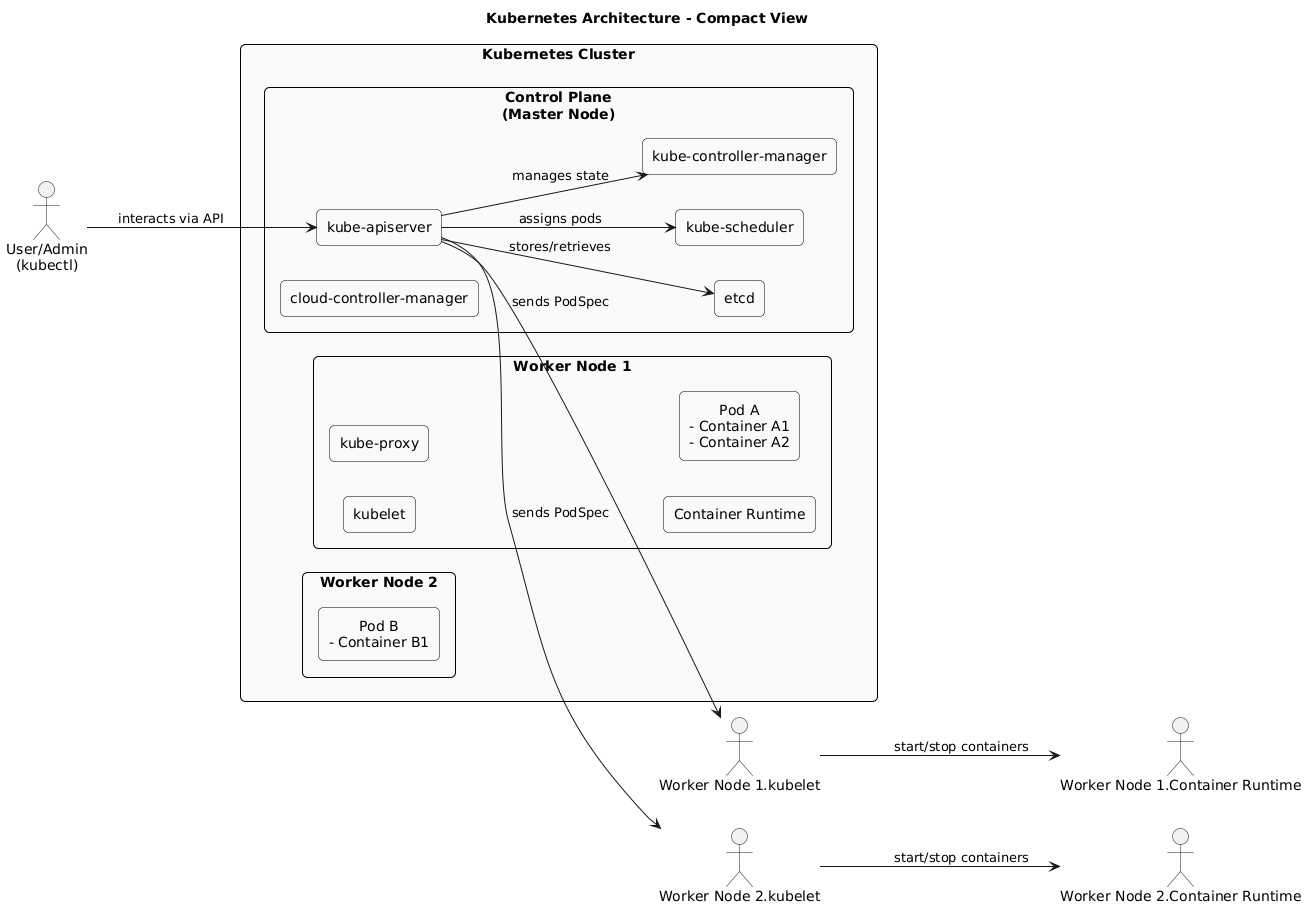
In-Depth Explanation for The Kubernetes Control Plane & Worker Nodes
Kubernetes operates on a declarative model: you define the desired state of your application (e.g., “I want 3 instances of my web server running version X”), and Kubernetes continuously works to make the actual state match that desired state.
1. The Control Plane: The Cluster’s Brain The Control Plane makes global decisions about the cluster (e.g., scheduling) as well as detecting and responding to cluster events. Its key components are:
kube-apiserver: This is the heart of the Control Plane and the primary management interface for the entire cluster. It exposes the Kubernetes API, which is used by external users (viakubectlor client libraries) and internal cluster components to communicate with each other. It processes and validates REST requests and updates the state inetcd.etcd: A distributed, consistent, and highly-available key-value store. It reliably stores the entire configuration and state of the Kubernetes cluster. All other components queryetcd(via the API Server) to understand the current and desired state.kube-scheduler: This component is responsible for assigning newly created Pods to suitable Worker Nodes. It makes decisions based on resource availability, constraints, affinity/anti-affinity rules, data locality, and other policies.kube-controller-manager: This runs a set of built-in Kubernetes controllers. Each controller is a background process that watches the shared state of the cluster through thekube-apiserverand works to bring the current state towards the desired state. Examples include:- Node Controller: Responsible for noticing and responding when nodes go down.
- Replication Controller (and ReplicaSet): Ensures that the correct number of Pods are running for a given application.
- Endpoints Controller: Populates the Endpoints object (i.e., joins Services & Pods).
cloud-controller-manager(if applicable): This component embeds cloud-provider-specific control logic, allowing Kubernetes to integrate with cloud provider APIs for resources like load balancers, storage volumes, and node management.
2. Worker Nodes: Where Applications Run Worker Nodes are the machines (VMs or physical servers) that run your containerized applications. Each Worker Node is managed by the Control Plane and contains the following essential components:
kubelet: An agent running on every Worker Node. It communicates with thekube-apiserverto receive Pod specifications (PodSpecs) and ensures that the containers described in those PodSpecs are running and healthy. It manages the lifecycle of containers on the node via the container runtime.kube-proxy: A network proxy that runs on each Worker Node. It maintains network rules on nodes, allowing network communication to your Pods from network sessions inside or outside of your cluster. It’s essential for implementing the Service concept (see next diagram).Container Runtime: The software that is responsible for running containers. Kubernetes supports several runtimes like Docker, containerd, and CRI-O. Thekubeletinteracts with the container runtime to pull images, start/stop containers, etc.
Pods: The Atomic Unit of Deployment A Pod is the smallest and simplest deployable unit in Kubernetes. It represents a single instance of a running process in your cluster. A Pod can contain one or more tightly coupled containers that share:
- Network namespace (same IP address and port space)
- Storage volumes
- CPU/memory resources (defined at the Pod level) Often, a Pod runs a single primary container, but it can also include “sidecar” containers for auxiliary functions like logging, monitoring, or proxying.
Managing Applications - Deployments, Services, and the Flow of Traffic
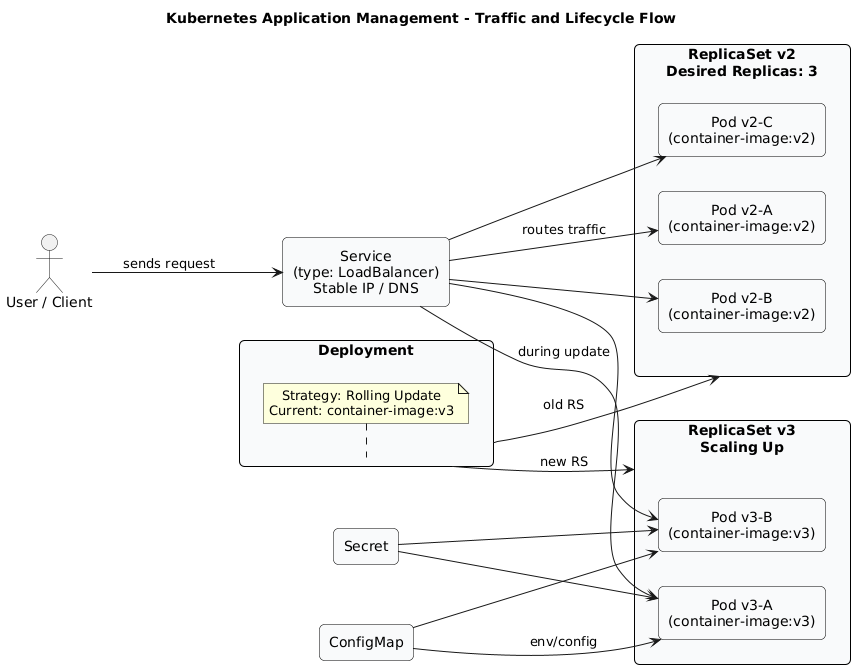
In-Depth Explanation for: Declarative Application Management
Kubernetes excels at managing the lifecycle of your applications using a declarative approach. You define what you want, and Kubernetes figures out how to achieve it.
1. Deployments: Managing Application Releases A Deployment is a Kubernetes object that provides declarative updates for Pods and ReplicaSets. You describe a desired state in a Deployment, and the Deployment Controller changes the actual state to the desired state at a controlled rate.
- Use Cases: Typically used for stateless applications (e.g., web servers, API backends).
- Key Features:
- Rolling Updates: Update your application to a new version with zero downtime by incrementally replacing old Pods with new ones.
- Rollbacks: Easily revert to a previous version if an update goes wrong.
- Scaling: Declaratively scale the number of application instances up or down.
- Self-Healing: Ensures the desired number of healthy Pods are always running by working with ReplicaSets.
- How it works: Deployments manage ReplicaSets. When you update a Deployment (e.g., change the container image version), it creates a new ReplicaSet and gradually scales it up while scaling down the old ReplicaSet.
2. ReplicaSets: Ensuring Pod Availability A ReplicaSet’s purpose is to maintain a stable set of replica Pods running at any given time. It ensures that a specified number of Pod instances are running. While you can use ReplicaSets directly, Deployments are the recommended way to manage replicated Pods as they provide more sophisticated update strategies.
3. Services: Stable Networking & Discovery Since Pods are ephemeral (they can be created, destroyed, and their IPs can change), Kubernetes needs a way to provide a stable network endpoint to access them. This is the role of a Service.
- Abstraction: A Service defines a logical set of Pods (usually determined by a selector based on Pod labels) and a policy by which to access them.
- Stable Endpoint: It provides a stable IP address and DNS name. Traffic sent to the Service is automatically load-balanced across the Pods that match its selector.
- Types of Services:
ClusterIP: (Default) Exposes the Service on an internal IP in the cluster. Reachable only from within the cluster.NodePort: Exposes the Service on each Node’s IP at a static port.LoadBalancer: Exposes the Service externally using a cloud provider’s load balancer.ExternalName: Maps the Service to the contents of anexternalNamefield (e.g., a CNAME to an external service).
- How it works:
kube-proxyon each Node watches the API Server for Service and Endpoint changes and updates network rules (e.g., iptables, IPVS) to route traffic accordingly.
4. Managing Configuration and Secrets
- ConfigMaps: Used to store non-confidential configuration data in key-value pairs. Pods can consume ConfigMaps as environment variables, command-line arguments, or as configuration files in a volume. This decouples configuration from container images.
- Secrets: Used to store sensitive information, such as passwords, OAuth tokens, and SSH keys. Secrets are stored more securely than ConfigMaps (though the default is base64 encoding, not strong encryption at rest without further configuration). Pods can consume Secrets similarly to ConfigMaps.
5. Namespaces: Organizing the Cluster Namespaces provide a way to divide cluster resources between multiple users or teams. They create virtual sub-clusters within the physical cluster, providing a scope for names and resource quotas.
Why This In-Depth Understanding Matters
A deeper understanding of Kubernetes architecture and its objects empowers you to:
- Design resilient and scalable applications: By leveraging Deployments, Services, and ReplicaSets effectively.
- Troubleshoot issues more effectively: Knowing how components interact helps diagnose problems.
- Optimize resource utilization: Understanding scheduling and resource requests/limits.
- Implement robust CI/CD pipelines: By interacting with the Kubernetes API to automate deployments and updates.
- Extend Kubernetes: Develop custom controllers or integrate with other tools in the cloud-native ecosystem.
Kubernetes provides a powerful and flexible platform, and mastering its core concepts is key to harnessing its full potential for modern application development and operations.